
MLOPS with Amazon Web Services
- Post On2020-08-29
- ByPradeep Natarajan
Since the last few years, machine learning has captivated the imaginations of a huge number of companies. Since everyone was doing machine learning so many companies approved budget for machine learning projects overnight but unfortunately most of the projects could not even make it to production. A recent report is a testimonial of such failures that states that only 22% of the machine learning projects see the light of production in the companies.
Such a low success rate might suggest that it is the lack of machine learning skills that is the responsible factor. However, a close inspection will reveal that the data scientists of these companies are actually able to create ML models but they are struggling to either deploy or maintain these models in production. And this is contributing to the failures of the machine learning projects.
Reasons behind Failure?
These failures should not come as a surprise because in such companies data scientists usually work in silos to create ML models but for getting it deployed and maintained in production they need help from developers and operations people who are two separate teams. Lack of collaboration between the teams is one major reason that impacts the project but also since developers and operations people have no clue about machine learning it creates more gaps and difficulty for maintenance.
Even the software industry used to have a similar problem many years back and they shifted towards the DevOps model to effectively streamline the software delivery process. DevOps methodology brought teams together for better collaboration and encouraged an end to end automation with the help of DevOps tools and technologies.
Learning from their project failures, the pundits of machine learning industries realized they need something similar to DevOps and hence the concept of MLOPs was born. As the name suggests, MLOPs is a spin-off from DevOps for machine learning projects.
Objective of MLOPs
Since MLOPs is derived from DevOps so most of its principles are applicable here as well, but the main objective of MLOPs is to quicker deployments and scale up the ML model over a period of time. This is important because unlike a traditional software system, an ML system can become stale with degraded performance due to the influx of new types of data. Hence MLOPs borrowed the popular methodology of CI/CD which stands for Continuous Integration and Continuous Deployments.
CI/CD is achieved with the help of pipelines which is nothing but an end to end automated process for creating, training, and deploying ML models by eliminating manual touchpoints.
There are many DevOps tools available to help you design your inhouse pipelines from scratch. However, there are cloud-based platforms like GCP, Microsoft Azure, AWS that also offer end to end MLOPs services. The advantage of using cloud services is that you don’t have to develop any MLOPs solution, instead you can just focus on creating and delivering ML models.
MLOPs with AWS Ecosystem
Amazon Web Service (AWS) is the leading cloud service provider and a pioneer in the industry. It offers a multitude of cloud services for different types of SaaS, PaS, and IaaS solutions and is powering thousands of well-known companies in the background.
In this post, we will understand how can we leverage different AWS services to build an MLOPs CI/CD pipeline. We will specifically cover the following cloud services of AWS -
1. AWS Sagemaker
2. AWS CodeCommit
3. AWS CodePipeline
4. AWS CodeBuild
5. AWS CodeDeploy
1) AWS Sagemaker

Sagemaker is the machine learning PaaS of the AWS machine learning stack and provides end to end ML services for building, training, and deployment of the machine learning model. It is a fully managed platform, this means you don’t have to worry about the provisioning of AWS resources, Sagemaker will take care of its own. Sagemaker offers Jupyter Notebook instances as a service that can be launched with a single click, however, you can also carry out your work right from Sagemaker’s GUI console without a notebook.
Let us take a closer look at the services of Sagemaker :
i) Build
This is where you set up the environment to train your model. You can navigate to the Sagemaker section of AWS, and configure Notebook Instances with the required Sagemaker instance type and S3 bucket for connecting with your data. Sagemaker also provides built-in templates for some of the popular ML algorithms that are specifically optimized for the AWS environment for high performance. Otherwise, you are free to write or bring your own ML code.
ii)Train
Once your model is built, it has to be trained with the data and for this purpose all the EC2 compute is provisioned by the Sagemaker in the background. You can initiate the training from Jupyter notebook by calling the fit function or by submitting it on the console.
sess = sagemaker.Session()
xgb = sagemaker.estimator.Estimator(containers[my_region],role, train_instance_count=1,
train_instance_type='ml.m4.xlarge',
output_path='s3://{}/{}/output'.format(bucket_name, prefix) ,
sagemaker_session=sess)
xgb.set_hyperparameters(max_depth=5,eta=0.2,gamma=4,
min_child_weight=6,subsample=0.8,
silent=0,objective='binary:logistic',num_round=100)
iii) Deploy
If you remember, we discussed how Data Scientists face challenges with the deployment of ML models. Sagemaker is surely going to make the life easy since for deployment we just need to write single line of code as below or by a single click from the console.
xgb_predictor = xgb.deploy(initial_instance_count=1,instance_type=’ml.m4.xlarge’)
The beauty of Sagemaker is that with just this line of code it automatically creates an HTTPS endpoint to serve the ML models. This means any external client can make an HTTPS request to your model and fetch the prediction as a response.
Behind the endpoints, Sagemaker automatically provisions one or many EC2 instances along with a load balancer. The load balancer plays an important role in distributing the incoming request across multiple EC2 instances for efficient performance. You can also configure the endpoints to autoscale to negotiate the surge in inference calls by the external systems.
Another useful feature of Sagemaker is that it allows to deploy multiple versions of the ML models so that data scientists can perform A/B testing.
2) AWS CodeCommit

AWS CodeCommit is a version control service that allows you to create your own GIT repositories. It is fully managed, hence all the maintenance, backup and scaling is taken care off on its own.
CodeComit is useful in the project where there are many data scientists working together, specially on AWS Sagemaker. It provides solution for better collaboration for version control and the good thing is that it supports all the exteral GIT commands and easy integration with other GIT tools.
3) AWS CodePipeline

AWS CodePipeline is a fully managed service for continuous delivery of code changes in a fast and quality manner. It helps you design an end to end pipeline with builds, testing and deployment of the code in an automatic way. It is very useful when you need to iteratively deploy changes of your machine learning model in production quite often.
It can be integrated with external 3rd party tools like GitHub, Jenkins and even to your own custom built plugins on your premises. It also offers a visualization of your pipeline process for easy tracking and monitoring purpose.
4) AWS CodeBuild

AWS CodeBuild is a fully managed service for building source code, perform test and create packages of code ready to be deployed. It allows you to scale multiple builds simultaneously and it takes care of all the resources in background without you need to worry about it.
CodeBuild is a very important enabler in creating the completely automated CI/CD pipeline buit using AWS CodePipeline.
Example of CI/CD MLOPs Pipeline with AWS
Having gone through relevant ML and Devops services of AWS cloud, let us now quickly go through an example of how a CI/CD pipeline will look like in the AWS ecosystem.
- The CodePipeline can be triggered either when the code is committed in the CodeCommit repository or at a predefined schedule.

2. Once pipeline is initiated, the CodeBuild service will then zip the Jupter Notebook code and other artifacts and stores them in a S3 bucket.

3. The Jupyter notebook code is now deployed in the test environment from the zip file and executed. When the notebook code is run by pipeline all the steps like preprocessing, model training, tuning and deployment takes place.

4. Once ML model is deployed in Test environment, a full fledged automated testing is performed.
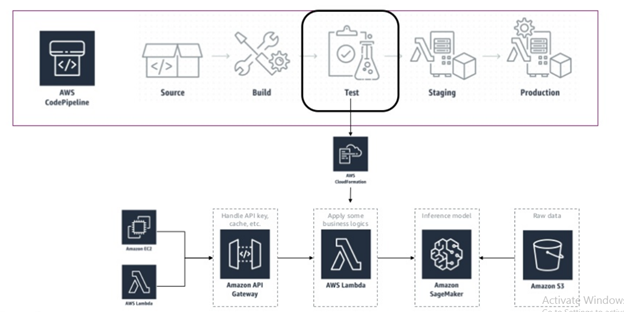
5. After the test quality gateway is passed the code can be deployed in a staging environment by following the similar build steps. This can be done after seeking automated approval from an authority. The deployment follows the same process, explained in point 3.

6. Finally, the deployment is done on the production environment by following similar steps and possibly after an approval.

Conclusion
In this article, we understood what MLOPs is and why is it important to address the alarming failure rates of ML projects in the companies. We also touched upon the AWS Sagemaker machine learning platform and AWS DevOPs serives and saw how they can be used to design a MLOPs CI/CD pipeline.
Reference
Post your comment